.png?table=block&id=b94a85e5-69f0-4bb3-90aa-d92e4ed78c64&cache=v2)
写在之前
想必大家一定都进行过在服务器之间传输文件的操作,以我个人的使用经验为例,我们可以使用
scp 来在两个不同物理机传输文件,如果需要长期保持文件的一致,还可以配合 crontab 脚本来使用。但经过学习和搜索之后,我发现了一种更优的方式,就是
rsync + crontab 来实现定时 增量 传输保持文件一致。rsync 功能很强大,网上的使用教程也很多,在这里不作赘述。相比工具的使用,其背后的原理可能更值得我们花时间去深入了解和学习。我也是想借助这个分享,和大家一起学习 rsync 算法的起源、思想以及改进。
全量同步 & 增量同步
rsync 是一个类 Unix 系统下用于同步文件的高效工具(算法),它能同步两处计算机的文件和目录,并且利用恰当的比较算法来减少数据的传输。
在 rsync 诞生的年代,网络带宽不像如今这么大,而要跨越因特网同步两个大文件,是非常奢侈的行为。
我们举一个实际的例子 🌰...
假设有这样一种场景:
在客户端,我们有一个记录着几十万条电话数据的文本文件,同时,服务端也存储这一个相同的文件作为备份。
需求:
同步客户端的数据到服务端
这时候,我们很容易想到下面的做法:
客户端程序监测到数据改变,就把客户端文件全部传输到服务端,并覆盖掉服务端的数据
这种方式简单直接且粗暴,缺点也很明显,对于大文件来说,传输的效率很低。
那么,有没有更优的解决方案呢?
当我们在客户端仅仅只增加一条电话记录时,我们肯定只希望传输增加的数据到服务端,服务端自动更新这条记录,这样不仅节约了带宽和时间,同样也能达到客户端和服务端的同步的目的。
于是,第二种方案诞生:
客户端程序监测到数据改变,只把新增的数据传输到服务端,服务端接收到客户端新增的数据后,再把新增数据整合进已有的数据中
小结
通过一起探讨上面的例子,我们对
rsync 算法的诞生背景有了一个初步的了解。上述方案中,第一种方案属于全量同步,第二种方案属于增量同步。rsync 算法就是解决上述增量同步问题的算法,即对于
fileSrc 和 fileDst 两个文件,我们想通过某种算法,只传输他们不同的部分,而不是使用暴力地将文件全部传输并覆盖老版本的文件。Rsync
问题
我们现在知道,rsync 想要解决的问题是,如果我们要同步的文件只传输不同的部分,那么就需要对两边的文件做 diff 对比。
但这两个文件在两个不同的机器上,无法做 diff,如果要对这两个文件直接做 diff,那么就需要把一个文件传输到另一台机器上做 diff。但这样一来,我们就传输了整个文件,这与我们只想传输不同部分的初衷相背。
我们现在知道有一种叫做「摘要」Digest 的东西,「摘要」其实就是对一个内容使用某种哈希算法,然后得到等长的一段数据,这段数据比原本的内容就要小得多了。
「摘要」一般用来验证数据的完整性,也可以验证原本的数据内容是否被篡改,因此,我们可以利用这一点来对文件块进行比较。
Okay,有了这一点共识之后,我们就可以继续探讨 Rsync 的基本算法了。
算法
我们把同步源文件名叫作
file_src ,同步目的文件叫作 file_dst 。- 分块 checksum 算法
- 一个叫 rolling checksum,是 32 位的弱 checksum,最开始使用的是 Mark Adler 发明的 adler-32 算法。
- 另一个是 128 的强 checksum 算法,最开始用 md4,后来用 md5 算法。
- 弱 hash 用于快速鉴别文件块的不同
- 强 hash 用于保证两文件块是相同的
我们把 file_dst 的文件平均分成若干小块,比如每块固定 512 字节,然后对每一块计算两个 checksum。checksum 本质上也是一个 hash 代码。
为什么要设置弱 hash 和强 hash 呢?
两个目的:
- 传输算法
- 如果我在
file_src这边的文件中间加了一个字符,这样后面的文件块都会移一个字符,就完全和file_dst不一样了,但理论上来说,我们只需要传一个字符就可以了。 - 如果这个checksum列表特别长,而我的两边的相同的文件块可能并不是一样的顺序,那就需要查找,线性的查找的速度又特别慢,因此我们还需要解决查找速度的问题。
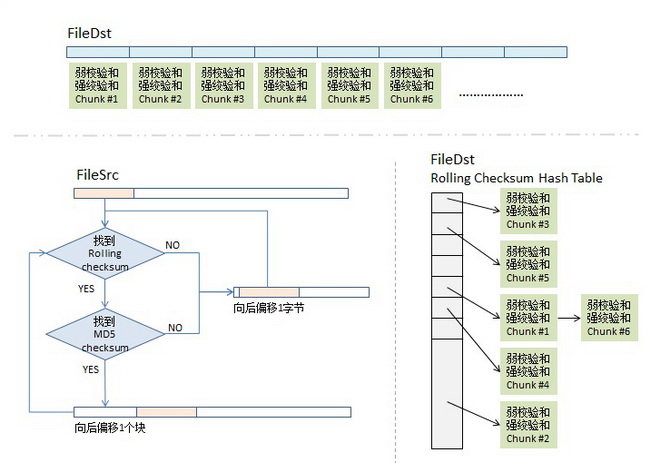
同步的目标端会把
file_dst 的 checksum 列表传给同步源,这个列表包含了三个东西,rolling checksum(32 bits) ,md5 checksum(128 bits) 和 文件块编号。在同步源端的机器在拿到这个列表后,会对
file_src 做同样的 checksum,然后和 file_src 的 checksum 做对比,找到改变了的文件块。但是,同步源端并不是简单的计算 checksum 并一一对照,为了保证效率和准确性,同步源端还有一个 checksum 查找算法。
同步源的算法主要解决了如下两个问题:
- checksum 查找算法
同步源端拿到
file_dst 的 checksum 后,会把这个数据存储到一个哈希表中,并用 rolling checksum 做 hash,这样就可以获得 O(1) 时间复杂度的查找性能。但是我们知道,hash 难免会发生碰撞,对于碰撞的情况,我们可以把碰撞的做成一个链表,发现碰撞的时候,再便利碰撞的链表即可。
- 对比算法
- 取
file_src的第一个文件块(假设是 512 字节),取出来以后做 rolling checksum 计算,并把计算结果放到 hash 表中查询 - 如果查到了,说明
file_dst中有潜在相同的文件块,但因为 rolling checksum 太弱了,很可能发生碰撞,于是还要计算 md5 的 128 bits 的checksum。这样一来,碰撞概率为2^-(32+128)=2^-160的概率发生碰撞,这样的概率非常小可以忽略。 如果 rolling checksum 和 md5 checksum 都相同,说明file_dst中有相同的块,我们需要记下这一块在file_dst下的文件编号。 - 如果
file_src的 rolling checksum 没有在哈希表中找到,就证明这块中有不同的信息,也就不用再计算 md5 了。 总之,只要 rolling checksum 或者 md5 其中有一个在file_dst的 checksum 哈希表中找不到匹配项,就会触发算法对file_src的 rolling 动作。 于是,算法会往后移动一个字节,取file_src中字节 2-253 的文件块做 checksum,然后再回到第 1 步。 - 经过这样多轮的 rolling 循环检查,我们就能找到
file_src相邻两次匹配中的那些文本字符,这些就是我们要往同步目标端传的文件内容了。
对比算法是最关键的算法,但是整体流程还是比较清晰:
Rolling Checksum
在学习 rsync 时,我一直不太理解什么是 rolling checksum,后面了解了之后,发现它的原理和算法相对简单。
我们应该要拆开来看:
- checksum 好理解,中文译作 校验和,顾名思义,用于校验目的地一组数据的和。本质上是一套哈希代码,但并不是任何的哈希计算函数都能够很好地用于 checksum。
- rolling 其实也好理解,滚动的意思。rolling 是最大的精髓,比如,我们往后前进 1 个字符的时候,不需要全部重新计算 checksum。也就是说,我们计算 checksum([0, 512])时,不需要重新计算从 1 到 513 的 checksum,而是在 [0, 512] 的 checksum 基础上直接算出来。
我举一个例子,有一串数字
123456789 ,假设 5 个长度作为一个块,那么第一个块就是 12345 ,可以表示为:1 * 10^4 + 2 * 10^3 + 3 * 10^2 + 4 * 10^1 + 5 * 10^0 = 12345如果我们前进 1 步,也就是要得到
23456 ,我们不必计算:2 * 10^4 + 3 * 10^3 + 4 * 10^2 + 5 * 10^1 + 6 * 10^0而是直接计算:
(12345 - 1 * 10^4) * 10 + 6 * 10 ^0也就是说,我们把
12345 的第一位去掉,再加上最右边一位,就能得到前进一步后的结果,这就是 rolling checksum 的算法。实现
我们根据前面所学的内容,来进行一个简单的 Python 版本实现。
设定块大小为 512 字节 → 4096 bit
block_size = 4096计算 checksum:
def signature(f):
while True:
block_data = f.read(block_size)
if not block_data:
break
yield (zlib.adler32(block_data), hashlib.md5(block_data).digest()) 实现一个 file_src 端的用于对比的哈希表
class RsyncLookupTable(object):
def __init__(self, checksums):
self.dict = {}
for block_number, c in enumerate(checksums):
weak, strong = c
if weak not in self.dict:
self.dict[weak] = dict()
self.dict[weak][strong] = block_number
def __getitem__(self, block_data):
weak = zlib.adler32(block_data)
subdict = self.dict.get(weak)
if subdict:
strong = hashlib.md5(block_data).digest()
return subdict.get(strong)
return None用于查找不同数据块的函数
def delta(sigs, f):
table = RsyncLookupTable(sigs)
block_data = f.read(block_size)
while block_data:
block_number = table[block_data]
if block_number:
yield (block_number * block_size, len(block_data))
block_data = f.read(block_size)
else:
yield block_data[0]
block_data = block_data[1:] + f.read(1)用于增量更新 file_dst 的函数
def patch(outputf, deltas, old_file):
for x in deltas:
if type(x) == str:
outputf.write(x)
else:
offset, length = x
old_file.seek(offset)
outputf.write(old_file.read(length))完整代码
from typing import Union
import zlib
import hashlib
block_size = 4096
def signature(f):
while True:
block_data = f.read(block_size)
if isinstance(block_data, str):
block_data = block_data.encode()
if not block_data:
break
yield (zlib.adler32(block_data), hashlib.md5(block_data).digest())
class RsyncLookupTable(object):
def __init__(self, checksums):
self.dict = {}
for block_number, c in enumerate(checksums):
weak, strong = c
if weak not in self.dict:
self.dict[weak] = dict()
self.dict[weak][strong] = block_number
def __getitem__(self, block_data: Union[str, bytes]):
if isinstance(block_data, str):
weak = zlib.adler32(block_data.encode())
else:
weak = zlib.adler32(block_data)
subdict = self.dict.get(weak)
if subdict:
strong = hashlib.md5(block_data).digest()
return subdict.get(strong)
return None
def delta(sigs, f):
table = RsyncLookupTable(sigs)
block_data = f.read(block_size)
while block_data:
block_number = table[block_data]
if block_number:
yield (block_number * block_size, len(block_data))
block_data = f.read(block_size)
else:
yield block_data[0]
block_data = block_data[1:] + f.read(1)
def patch(outputf, deltas, old_file):
for x in deltas:
if type(x) == str:
outputf.write(x)
else:
offset, length = x
old_file.seek(offset)
outputf.write(old_file.read(length))
if __name__ == "__main__":
with open("file_dst.txt", "r") as f_dst:
sigs = signature(f_dst)
with open("file_src.txt", "r") as f_src:
deltas = delta(sigs, f_src)
with open("file_dst.txt", "w") as outputf:
patch(outputf, deltas, f_src)总结 & 延伸思考
我们先从实际工作和生活中的例子切入,在工具层面先知道了 scp,然后知道了增量更新的方案 rsync。
然后更进一步,从工具背后的算法和原理入手,层层拆解,知道了 rsync 背后的逻辑,然后再用一门语言 Python 来实现 rsync 算法,完成了从理论到上手实践的整个流程。
rsync 是很久之前被提出来的算法了,本次分享的内容是基于最初的几个版本来展开的,相信过去这么长的时间,应该有一些我们能够改进的地方,这里留下一道会后思考,请大家思考一下可以从哪些方面着手进行优化。
在学习过程中,还有一点我认为值得和大家再分享一下:
在对比
file_src 和 file_dst 两者的不同时,我们运用了 hash 表,通过分别判断弱 checksum 和强 checksum 是否在已有哈希表中存在来判断是否属于相同数据块。这个算法和思想与布隆过滤器有异曲同工之妙,布隆过滤器有两个特点:判断存在的,不一定存在;判断不存在的,一定不存在。所以,布隆过滤器是有误差的。
在 rsync 的对比算法中,同样也可能存在误差,因此,用于对比的哈希表不仅使用了弱 checksum,还增加了强 checksum 作为第二道保险改进了对比的算法。
感兴趣的同学也可以在后面自行了解一下布隆过滤器。
参考
原作者的报告:
报告 pdf 版本: